Hyper Text Transfer Protocol
Overview
Overview of basic architecture of the web:
Simple textual protocol.
URI's.
Basic methods
GET,POST,HEAD.Web services, additional methods.
REST
GraphQL.
Why Was the WWW Successful
Numerous earlier attempts like CORBA to build distributed systems.
WWW succeeded because:
- it used a very simple protocol with general methods, rather than those specialized to a specific domain.
- it initially was built for humans; it was only later realized that it could also be used by machines.
HTTP/1.x: a Simple Textual Protocol
HTTP 1.x is a text protocol (not binary).
It is easy for humans to debug the protocol as the protocol data is directly human-readable.
Often protocol data consists of header lines separated from textual body by an empty line.
A header consists simply of a header name separated from its value by a single colon
:.Headers describe type of content.
Body may need to be encoded especially if it is binary.
An Example using netcat
The netcat program allows interacting with network servers:
$ nc -C www.binghamton.edu 80 #-C: send end-of-line as CRLF
GET / HTTP/1.1 #HTTP request
Host: www.binghamton.edu #mandatory header
#empty line ends request headers
HTTP/1.1 301 Moved Permanently
... #response headers
Location: https://www.binghamton.edu/
Content-Length: 235
Content-Type: text/html; charset=iso-8859-1
#empty line ends response headers
<!DOCTYPE HTML PUBLIC "-//IETF//DTD HTML 2.0//EN">
<html><head>
<title>301 Moved Permanently</title>
</head><body>
...
</body></html>
$
Interacting with a Web Server
Request consists of a request method like
GET, a URL (relative to the server) and the version likeHTTP/1.1. This can be following by zero-or-more name:value header lines. The request headers are terminated by an empty line. This may be followed by an entity body depending on the request.The response is similar except that it starts with a line containing a protocol version and status.
Purely textual protocol makes it easy for humans to use these kinds of general network programs to interact with web sites.
Another program useful for interacting with web sites is curl.
Identifying and Locating Web Resources
A Uniform Resource Identifier (URI) is an identifier for an abstract or physical resource.
A Uniform Resource Locator (URL) is a URI with an access method which allows locating a resource.
A Uniform Resource Name is a URI which uses specific namespaces to persistently identify a resource.
Relative URLs are relative to some base URL.
Original RFC is quite readable.
There is confusion about the above differences, URI and URL often used interchangeably; see this.
URI Components
Consider the URI
<http://zdu.binghamton.edu/cgi/echo.mjs?name=john&name=mary#label>
- Scheme
All URI's start with an identifier giving the specification it follows. This is followed by a
:char. The example uses schemehttp.- Authority
Specifies the naming authority for the resource. Preceeded by a
//. The example has the authorityzdu.binghamton.edu, which corresponds to a hostname in the domain-name system (DNS).Can contains user-info (preceeded by an
@), a host-name or IP address and a port number (preceeded by a:).
URI Components Continued
- Path
Separated from the authority by a
/character. The example has the pathcgi/echo.mjs.It is terminated by a subsequent
?or#character.- Query
Indicated by the first
?after the path and is terminated by a#character (or the end of the URI). The example has the queryname=john&name=mary.- Fragment
Identifies a secondary resource (relative to the primary resource). Follows a
#character after the query. The example has a fragmentlabel. This is not sent to the server.
URI Examples
https://zdu.binghamton.edu:8080/cgi-bin/hello.rb ?name1=fred&name2=john#label http://128.226.116.131/ mailto:umrigar@binghamton.edu file:///home/umrigar/cs580w/ #absolute paths only urn:isbn:978-0596517748
URI Encoding
Encode characters which may have reserved meanings within a URL.
RFC 3986 reserves special characters like
/,?and&.Special characters need to be escaped using
%hh where hh is the ASCII code for the character.Slash
/represented as%2F.Question-mark
?represented as%3F.Ampersand
&represented as%26.
Alphanumerics, hyphen
-, underscore_, period.and tilde~never need to be escaped.Characters need not be URI-escaped if used within a context where they are not special; for example,
/does not need to be escaped within a query string.
JavaScript URL Constructor
new URL(url, base)
Construct a new URL object from string
url. Ifurlis relative, then construct URL relative tobase.hrefproperty of constructed object takes care of encoding.URLSearchParamsvery useful for encoding query string.More convenient than legacy
encodeURI(string),encodeURIComponent(string),decodeURI(string)anddecodeURIComponent(string)Unfortunately, only partial support by Safari.
Do not confuse with nodejs legacy api.
URL Example
> u = new URL('test.cgi?name=john smith',
'http://example.com:8080')
URL {
href: 'http://example.com:8080/test.cgi?
name=john%20smith',
origin: 'http://example.com:8080',
protocol: 'http:',
host: 'example.com:8080',
hostname: 'example.com',
port: '8080',
pathname: '/test.cgi',
search: '?name=john%20smith',
searchParams: URLSearchParams {
'name' => 'john smith'
},
hash: ''
}
URL Example Continued
> u.hash = 'first'
'first'
> u.href
'http://example.com/test.cgi?name=john%20smith#first'
> u.searchParams.append('colors', 'blue&green')
undefined
> u.href
'http://example.com:8080/test.cgi?name=john+smith&
colors=blue%26green#first'
>
HTTP Overview
A client makes a request for a resource on a server.
A server returns a response which is a representation of the requested resource.
Both request and response are text containing header lines separated from body by a empty line.
HTTP does not care about headers it does not understand. Postel's Principle ensures robustness: Be conservative in what you do, be liberal in what you accept from others.
Uniform Resource Locators (URLs) are used for identifying resources.
Stateless Protocol
As far as HTTP goes, no state is stored on the server.
HTTP does not in any way associate requests from the same client.
State is maintained by sending some identification information with each request. This is then used to access state stored on the server.
Information identifying state is often sent via cookies or URL parameters.
Statelessness makes it possible for the protocol to scale.
HTTP Method Properties
Two properties which allow building robust applications in the presence of errors:
- Safe method
Should not change application state on the server.
- Idempotent method
Multiple identical requests have the same effect as a single request.
The GET Method
Requests a representation of a resource.
Should be implemented to be safe and idempotent.
No body in request.
Has format
GETresourceHTTP/version, where resource is the path to the resource on the server and version is the version of the HTTP protocol:1.1widely used;2.0(binary protocol) is being deployed.Can be cached.
Allowed in HTML forms.
The POST Method
Sends data to server. Usually used for submitting forms or creating subordinate resources (subordinate to the requested URL).
No safety or idempotency guarantees.
If the
Content-Typeheader isapplication/x-www-form-urlencoded, then the body consists name=value pairs separated by&characters. Non-alphanumeric characters are %-encoded.Content-Typeofmultipart/form-dataoften used for binary data as when uploading a file.Cannot be cached. Often breaks browser back button on poorly implemented web sites.
Allowed in HTML forms.
The HEAD Method
Like
GETbut response does not include a body.Used to query the status of a resource.
Helps with caching.
Should be implemented to be idempotent and safe.
Cacheable.
No response body.
The PUT Method
Can be used for creating or updating resource at specified URI.
When updating, the specified object completely replaces resource.
Obviously unsafe, but should be implemented to be idempotent; hence if the same PUT request is repeated multiple times, the effect is the same as a single PUT request.
Cannot be cached.
Not allowed in HTML forms.
No response body.
The PATCH Method
Can be used for partial modifications of resource at specified URI.
Unlike
PUT, request body only specifies changes to resource.No safety or idempotency guarantees; however, there is no reason a particular application cannot set up
PATCHoperations to be idempotent.Cannot be cached.
Not allowed in HTML forms.
May not have response body.
The DELETE Method
Used to delete resource specified by URL.
Obviously unsafe, but should be implemented to be idempotent; hence if the same DELETE request is repeated multiple times, the effect is the same as a single DELETE request.
Cannot be cached.
Not allowed in HTML forms.
May not have response body.
Put vs Post for Creation
Use
PUTwhen client specifies URL for created resource.For example, if a user is created at URL
/api/users, but theloginId(from the request body) is used as the ID for the user, then issue aPUTto/api/users. The URL for the newly created user will be/api/users/jsmithfor client-providedloginIdjsmith.Use
POSTwhen server specifies URL for created resource. So created resource is subordinate to an existing resource.For example, if a user is created at URL
/api/users, but the ID for the user is generated by the server, then issue aPOSTto/api/users. The URL for the newly created user will be/api/users/u-4328a7efor server-generated IDu-4328a7e.
HTTP Status Codes
- 1xx
Informational messages.
- 2xx
Used to indicate success.
- 3xx
Used to indicate redirection via the
Locationheader.- 4xx
Used to indicate a client error.
- 5xx
Used to indicate a server error.
Some Notable Status Codes
See HTTP Status Codes:
- 200
Ok.
- 201
Created. A new resource has been created. Most specific URI for new resource given by
Locationheader in response.- 204
No content. Success but no content.
- 301
Moved permanently. Resource moved permanently to URL specified by
Locationheader.- 302
Found. Moved temporarily to URL specified by
Locationheader. Became synonymous with 303.- 303
See other. Resource can be retrieved by doing a
GETto URL specified byLocationheader.- 304
Conditional get. Used for caching.
- 307
Moved temporarily to URL specified by
Locationheader.
Some Notable Status Codes Continued
- 400
Bad request. Client sent an incorrect request.
- 401
Unauthorized. Requires authentication.
- 404
Not found. No resource at specified URL.
- 409
Conflict. Request conflicts with current state of resource.
- 500
Internal server error.
Post-Redirect-Get Pattern
Create and update actions use following PRG Post-Redirect-Get form submission pattern:
Form is displayed.
User submits form using POST.
If submission contains errors, form is redisplayed with errors. Else go to next step.
Server sends a redirect to browser with
Locationheader set to the success URL (which can be determined dynamically).Browser automatically follows the redirect by issuing a GET to the success URL.
A disadvantage of this pattern is that any parameters for the success page need to be sent as query parameters in success URL.
Post-Redirect-Get Pattern Example
Browser displays shipping info form on say
/cart/ship-info.html.User fills in shipping info and submits form using
POST.If form submission has errors, then form is redisplayed at
/cart/ship-info.html, along with user input and error messages.If form submission is successful, then the server redirects the browser to
/cart/billing-info.html.The browser automatically follows the redirect by issuing a
GETto/cart/billing-info.html.Browser displays returned page at
/cart/billing-info.html.
It is possible that the billing info is different depending on whether
the user is domestic or foreign. This can be determined based on
the address submitted by the shipping info form and the redirect URL
could be either /api/billing-info.html?userType=domestic or
/api/billing-info.html?userType=foreign.
Web Services
The web is one of the most successful distributed systems ever built.
Web services allow access to web resources by programs rather than humans.
Programs can harvest information from the web by scraping information from HTML web pages.
HTML can be authored so that information can be accessed easily by programs (often true of current web pages), but information is often hidden within text.
HTML is only one representation for information; other representations like JSON and XML are primarily intended to be read by programs.
Additional HTTP methods available for web services (human web largely uses only GET, POST and HEAD).
SOAP
Originally stood for Simple Object Access Protocol.
A style of web services.
Original motivation appeared to be tunneling through corporate firewalls using web ports.
Largely remote procedure call using HTTP and XML. Many implementations did not really use web architecture.
Huge collection of standards. Lots of tooling.
Will not cover further in this course even though it is still quite popular (mainly legacy compatibility).
Representational State Transfer
Acronym REST: Representational State Transfer.
An architectural style.
Post-documentation of web architectural style by Roy Fielding.
REST web services use URL's to represent resources and HTTP methods as the actions on the resources.
REST Web Services
Features of REST web services:
HTTP messages.
URI's.
Representations.
Links (HATEOAS).
Caching.
Already discussed HTTP messages and URI's.
Representations of Resources
A resource can be thought of like an object.
Objects can contain other objects (value objects). Similarly resources can embed other resources.
Objects can reference other objects (via object references). Similarly resources can link to other resources.
Resources are named by URI's.
Resources can have multiple representations.
JSON Representation
JSON is a popular way of representing resources.
{
"id": "1234",
"name": "John Smith",
"email": "jsmith@mail.example.com"
}
XML Representation
<?xml version="1.0" encoding="ISO-8859-1"?> <person> <id>1234</id> <name>John Smith</name> <email>jsmith@mail.example.com</email> </person>
The first line is a XML declaration.
<element>...</element>is an element.
Alternate XML Representation
Can move atomic information into element attributes.
<?xml version="1.0" encoding="ISO-8859-1"?> <person id="1234"> <name>John Smith</name> <email>jsmith@mail.example.com</email> </person>
Well-Formed vs Valid XML
If XML nesting structure syntax is correct, then it is said to be well-formed.
No restriction on vocabulary (element names, attribute names) of well-formed XML.
It is possible to restrict element and attribute names and their permitted containment relationships using an external specification. XML which meets such restrictions is said to be valid. Some alternatives for specifying the restrictions:
Document Type Definitions (DTDs).
XML Schema.
RELAX NG.
Content Negotiation
Client can indicate what kind of representation it wants by using a specific extension like
.xmlor.jsonin the URL as inhttp://example.com/api/person.json?id=1234 http://example.com/api/person.xml?id=1234and the server needs to honor these URLs.
Client can indicate its preferences using a special
ACCEPTheader in its request:GET /person?id=1234 ... ACCEPT: application/json
HyperText As The Engine Of Application State
Acronym HATEOAS.
The state of an application is maintained in a document (JSON, XML, HTML) returned to a client. This client state is often linked to server-side state using cookies or URLs.
The document contains links or forms.
Client transitions to a new state by following a link or filling-in and submitting a form.
A browser application is a state machine with the browser displaying a window into the current application state and state transitions taken by following links or submitting a form.
HATEOAS for an E-Commerce Site
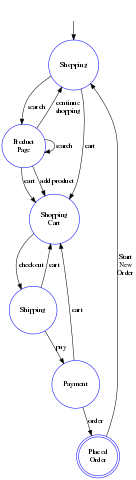
Handling Multiple Results
A query may return 100s or 1000s of results. Need to provide a way to scroll or page through results. Can use offset or id based cursors.
Current Result(s): Use a field
selfor link withrelset toself. Example:
{ rel: 'self', href: 'http...?offset=15&count=5' }.Next Result(s) : Use a field
nextor link withrelset tonext. Example:
{ rel: 'next', href: 'http...?offset=20&count=5' }Previous Result(s): Use a field
prevor link withrelset toprev. Example:
{ rel: 'prev', href: 'http...?offset=10&count=5' }
REST Evaluation
Problems with needing multiple requests. For example, a
GETfor ausermay return a list of friend ID's, needing multiple subsequentGETrequests to get the names of the friends.Too much data returned. So in the above example, when
GETis requested for each friend of auser, theGETmay return all information for the friend but only the name is needed.Possible to filter returned information using query parameters.
HATEOAS has never caught on. One problem is that the semantics of link relations are not standardized so that programs can understand what a link will do. There are various attempts: IANA collects relations defined by different standards; schema.org is an attempt to describe structured data across multiple domains, motivation may be to assist with Search Engine Optimization (SEO).
GraphQL
Typed schema.
Query or mutation requests.
Returned objects have same "shape
" as objects in query request.Single endpoint.
Discourage versioning of web APIs, since client can specify exact data to be retrieved in request.
From Facebook.
GraphQL Types
Primitive scalar types
Int,Float,Boolean,String,IDand enumeration types declared usingenum.Not null modifier using
!after type.{ name: String!}.List modifier:
{ friends: [Friend!] }.Allows usual product data type:
type Point { x: Float y: Float } Circle { id: ID origin: Point radius: Float }Sum types:
union Shape = Circle | Rect | ... ;
Interfaces.
GraphQL Evaluation
All data must be typed, untyped data typically handled by serializing to/from JSON.
Looks a lot like RPC with a modern type system, filtering and a neat query language.
Moves away from REST goal of programmatic web being as extensible as the human web.